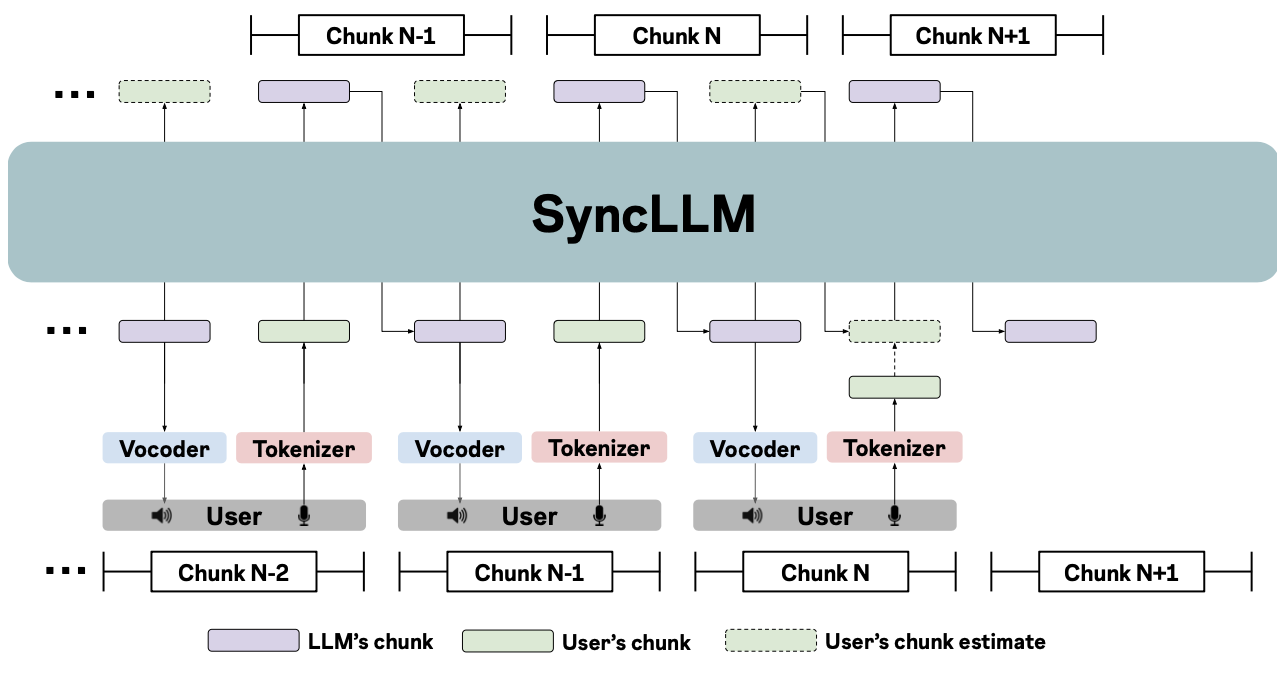
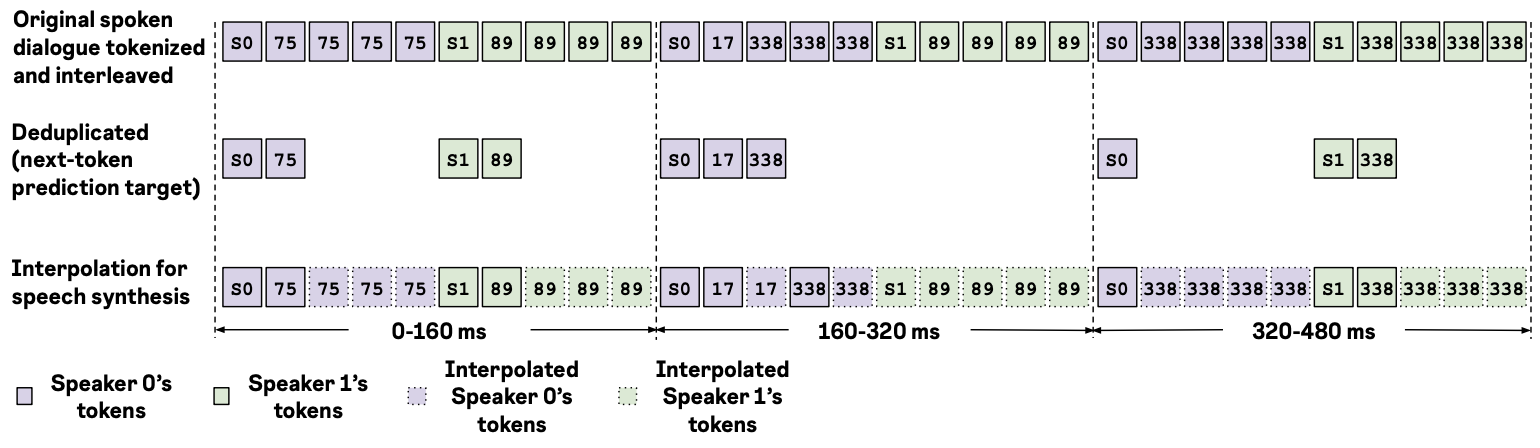
Latency tolerant interaction
SyncLLM is an auto-regressive decoder-only transformer model that can function as a full-duplex dialogue agent. In the following figure, at current time step (chunk N in the figure), SyncLLM’s context contains interleaved chunks of the LLM’s speech until the current chunk, and the user’s speech corresponding to all but the current chunk. To be in synchrony with the user, the LLM must generate its next chunk (chunk N+1) before the end of the current chunk. As a result, SyncLLM first generates an estimated user’s chunk, which is in-turn appended to the context and used to predict its next chunk.